







开云体育 
Deepseek背景综述及在金融领域应用场景初探(附下载)开云体育官方
 2025-11-28
2025-11-28 浏览次数:
次
浏览次数:
次 返回列表
返回列表开云体育[永久网址:363050.com]成立于2022年在中国,是华人市场最大的线上娱乐服务供应商而且是亚洲最大的在线娱乐博彩公司之一。包括开云、开云棋牌、开云彩票、开云电竞、开云电子、全球各地赛事、动画直播、视频直播等服务。开云体育,开云体育官方,开云app下载,开云体育靠谱吗,开云官网,欢迎注册体验!DeepSeek-R1 模型于 2025 年 1 月 20 日上线,随即引发了大量讨论与用户的快速增长。截至 2025 年 1 月 31 日,DeepSeek 日活跃用户就已经突破了 2000 万,一举超过豆包成为国产日活用户最多的大模型,同时也成为全球用户增长最快的 AI 产品。
DeepSeek-R1通过混合专家(MoE)架构与动态路由技术,将推理成本压缩至GPT4 Turbo 的 17%,低成本、高性能的叠加使得需求端爆发式增长:一方面网页端及手机端应用频频出现服务器拥挤无法返回答案情况;另一方面各大企业争先本地化部署 DeepSeek 大模型。DeepSeek-R1 模型的问世不仅刷新了 AI 应用的普及速度,更标志着大模型竞争从“算力军备竞赛”向“终端侧普惠化”的转向。我们认为 DeepSeek-R1 模型在 2025 年 1 月引发的轰动只是中国 AI 行业快速发展的开始,伴随着低成本高性能大模型在各行各业落地部署以及在不同应用场景下对于 AI 大模型应用的开发,DeepSeek-R1 将会在更多领域展现出更大的影响力。
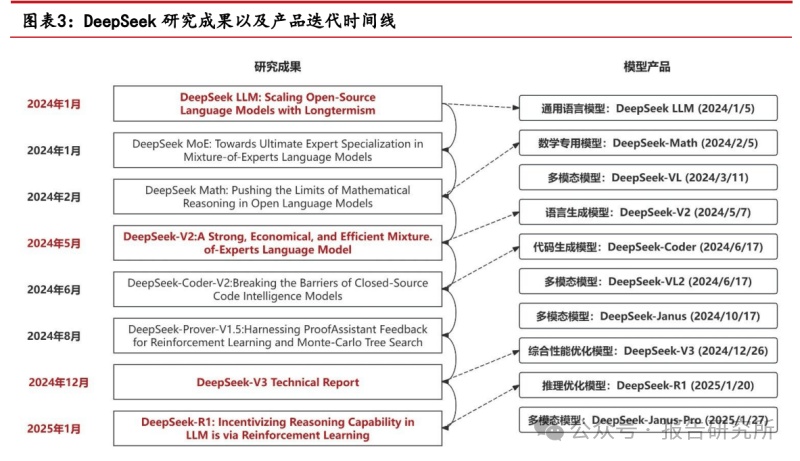
DeepSeek LLM 模型发布于 2024 年 1 月,该论文主要涵盖模型训练、缩放定律研究、对齐优化及评估等工作。
扩展法则,通常用于阐释模型性能与模型规模、训练数据规模、计算资源规模之间的联系,即随着这三者的增大,模型性能提升所呈现出的可预测规律。它指出,在增加模型参数、扩大训练数据量以及投入更多计算资源的情况下,模型性能往往会按照特定的、可预测的模式得到优化。
研究表明,数据质量在模型和数据的最优扩展分配策略中起着关键作用。具体来说,高质量数据会使增加的计算预算更多地向模型扩展倾斜。在 DeepSeek LLM 项目里,研究人员借助小规模实验,成功对大规模模型的性能做出准确预测。这一成果为模型的扩展方向提供了有力的指引,助力在模型开发过程中更合理地规划资源,提升模型性能。
主要介绍了 DeepSeek-V2 这一强大的混合专家(MoE)语言模型,同时设计了创新架构:采用 Transformer 架构,设计 Multi-head Latent Attention (MLA)。文章阐述了模型架构、预训练、对齐优化等工作,并展示了其在性能、训练成本和推理效率方面的优势。
通常情况下,传统的 Transformer 模型会运用多头注意力(MHA)机制。然而在模型生成内容的过程中,该机制的键值(KV)缓存却成了阻碍推理效率提升的关键因素。为了解决这一问题,研究人员提出了多 Query 注意力机制(MQA)和分组注意力机制(GQA)。而在这篇文章中,主要介绍了 MLA(Multi-Head Latent Attention)在性能表现上优于 MHA,并且在减少 KV 缓存数量方面效果显著。
混合专家模型(Mixture of Experts,简称 MoE)属于集成学习技术的一种,它的核心原理是整合多个 “专家” 模型的输出,以此来增强整体模型的性能表现。在MoE 的架构里,存在一个 “门控网络”(gating network),其主要职责是判断针对特定输入,应由哪一个或哪几个专家模型进行处理。每个专家模型都具备独特的能力,各自擅长处理输入空间中的特定部分内容,门控网络则依据输入的具体情况,将任务精准分配给最为匹配的专家。MoE 的主要优势在于:1)在不显著提升计算成本的前提下,拓展模型的容量。这是由于在处理任意给定的输入时,仅有部分专家会被激活参与运算,避免了整体计算资源的过度消耗。2)让模型更“专业”。不同的专家可针对数据中的不同模式与特征进行学习,从而达成模型专业化,全方位提升模型的整体性能,让模型在复杂任务处理中表现更为出色。3)实现稀疏激活。借助门控机制,在运行过程中,仅让部分网络处于激活状态,这种方式极大地提高了模型的运行效率,减少了不必要的资源浪费。
在传统的强化学习方法里,像近端策略优化(PPO,Proximal Policy Optimization),一般都需要一个规模与策略模型(policy model)相近的 Critic 模型。Critic 模型的作用是对策略的好坏进行评估,以此为策略的优化提供方向。不过,训练 Critic 模型这一过程本身会额外增加计算成本。而 GRPO 的关键优势就在于,它舍弃了传统的 Critic 模型,进而节省了训练过程中这部分的开销。从而降低强化学习(RL)训练成本。GRPO 之所以可以舍弃 Critic 模型,是因为它借助了 “群体分数”(group scores)来估计基线(baseline)。基线主要用于衡量当前策略的平均表现,优势函数则体现了奖励值相较于基线 DeepSeek-V3
这篇论文在 DeepSeek-V2 论文基础上介绍了 DeepSeek-V3 这一具有 6710 亿参数的混合专家语言模型,主要围绕模型架构、训练、评估及应用等方面展开研究,致力于提升开源模型性能,推动语言模型向通用人工智能发展。
Multi-Token Prediction 的目的在于,通过促使模型在每个位置对多个未来令牌进行预测,以此提升模型的性能表现。其核心原理是,通过加大训练信号的密度,帮助模型更有效地规划自身的内部表示,进而增强对后续令牌的预测能力。
FP8 混合精度训练框架旨在通过降低数据精度来提升计算效率、减少内存占用和降低训练成本,同时尽量保持模型的性能和准确性。主要优点为:1)提高计算效率:FP8 计算所需的资源更少。尤其在 GPU 等硬件加速器上,计算速度可比 FP32 快数倍,能显著缩短训练时间。2)降低内存占用:FP8 数据占用的内存空间仅为 FP32 的四分之一,可支持更大规模的模型训练。3)保持模型精度:通过合理的混合精度策略,如在不同阶段使用不同精度的数据类型,FP8 训练可以保持与全精度训练相近的模型精度。
这篇论文主要介绍了 DeepSeek-R1 和 DeepSeek-R1-Zero 这两个推理模型,展示了通过强化学习提升语言模型推理能力的研究成果,并探索了模型蒸馏在提升小模型推理能力方面的应用。
DeepSeek-R1-Zero 模型的推理能力提升,不是人为教它该怎么做,而是通过强化学习,模型自己学会的。
研究人员在实验中发现,DeepSeek-R1-Zero 模型在训练初期时稳定性很差,为了解决这一问题,引入了“冷启动数据”。在 DeepSeek-R1 的强化学习环节开展之前,团队构建并收集了少量高质量的长思维链数据(long CoT data)。这些数据就如同为模型提供了一系列高质量的“范例”,使得模型在正式进入强化学习阶段前,预先掌握有效推理和生成答案的方法。这好比在跑步前,教练会先示范正确的跑步姿势与技巧,让学习者提前熟悉和适应。
DeepSeek-R1 能够在极低训练成本下实现与 ChatGPT-o1 相当的性能,主要依赖于其创新的训练算法设计、硬件优化的注意力机制以及高效的数据利用策略。
